Dalam era digital, data telah menjadi bahan bakar yang menggerakkan kemajuan. Salah satu jenis data yang fundamental adalah data yang berisi sederet karakter. Data ini membentuk dasar untuk berbagai aplikasi, mulai dari pemrosesan teks hingga penyimpanan data.
Data sederet karakter terdiri dari urutan karakter yang mewakili informasi. Karakter-karakter ini dapat berupa huruf, angka, simbol, atau spasi. Jenis data ini sangat penting untuk mewakili teks, dokumen, dan berbagai bentuk komunikasi.
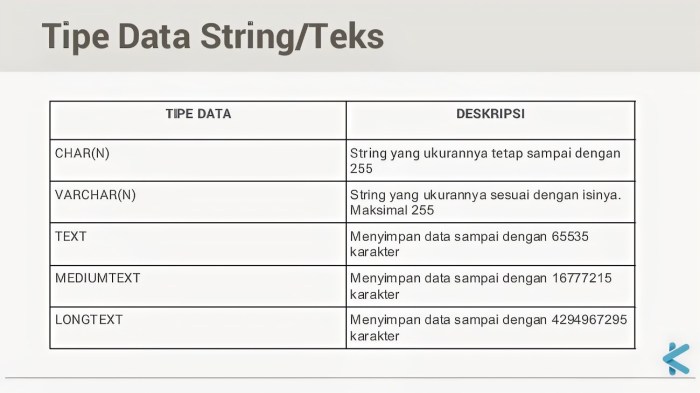
Definisi Data Berupa Sederet Karakter

Data yang berisi sederet karakter adalah jenis data yang terdiri dari urutan karakter yang bermakna.
Contoh data yang termasuk dalam kategori ini meliputi:
- Teks
- Kode
- String
Jenis-jenis Data Sederet Karakter
Data sederet karakter dapat diklasifikasikan berdasarkan jenisnya, yang masing-masing memiliki karakteristik dan kegunaan yang berbeda.
Data Sederet Karakter ASCII
- Menggunakan 7 bit untuk merepresentasikan setiap karakter.
- Terdiri dari 128 karakter, termasuk huruf besar dan kecil, angka, tanda baca, dan simbol.
- Digunakan secara luas dalam sistem komputer dan komunikasi.
Data Sederet Karakter Unicode
- Menggunakan 16 atau 32 bit untuk merepresentasikan setiap karakter.
- Mendukung lebih dari 1 juta karakter, termasuk karakter dari berbagai bahasa dan simbol.
- Memungkinkan representasi karakter yang lebih kompleks dan kaya.
Data Sederet Karakter UTF-8
- Representasi variabel-panjang dari Unicode.
- Menggunakan 1 hingga 4 byte untuk merepresentasikan setiap karakter.
- Kompatibel dengan ASCII dan banyak digunakan di internet.
Pengodean Data Sederet Karakter

Pengodean data sederet karakter merupakan proses merepresentasikan karakter teks menggunakan nilai numerik. Metode ini memungkinkan komputer untuk menyimpan, memproses, dan mentransmisikan data teks secara efisien.
Terdapat berbagai metode pengodean yang digunakan, masing-masing dengan kelebihan dan kekurangannya sendiri. Beberapa metode pengodean yang umum digunakan meliputi:
Pengkodean ASCII
- American Standard Code for Information Interchange (ASCII) adalah metode pengodean 7-bit yang dapat merepresentasikan 128 karakter, termasuk huruf, angka, dan simbol.
- ASCII banyak digunakan dalam sistem komputer dan aplikasi, terutama untuk teks bahasa Inggris.
Pengkodean Unicode
- Unicode adalah metode pengodean yang dirancang untuk merepresentasikan karakter dari semua bahasa di dunia.
- Unicode menggunakan sistem pengkodean 16-bit atau 32-bit, yang memungkinkan merepresentasikan lebih dari satu juta karakter.
- Unicode banyak digunakan dalam sistem operasi modern, aplikasi, dan situs web untuk mendukung teks multibahasa.
Pengkodean Lainnya
- Selain ASCII dan Unicode, terdapat juga metode pengodean lainnya, seperti Extended ASCII, UTF-8, dan UTF-16.
- Metode pengodean ini digunakan untuk tujuan tertentu, seperti mendukung bahasa yang berbeda atau meningkatkan efisiensi penyimpanan.
Operasi pada Data Sederet Karakter
Data sederet karakter merupakan kumpulan karakter yang disusun secara berurutan. Terdapat berbagai operasi yang dapat dilakukan pada data jenis ini, yang memungkinkan manipulasi dan analisis yang efektif.
Pembagian String
- Split: Membagi string menjadi beberapa bagian berdasarkan pembatas yang ditentukan.
- Substring: Mengekstrak bagian dari string yang ditentukan oleh indeks awal dan akhir.
- Slicing: Mirip dengan substring, tetapi memungkinkan penggunaan langkah untuk melompati karakter.
Penggabungan String
- Concatenation: Menggabungkan dua atau lebih string menjadi satu string.
- Interpolation: Menyisipkan nilai variabel ke dalam string.
- Formatting: Memformat string sesuai dengan pola tertentu, seperti tanggal atau mata uang.
Transformasi String
- Uppercase: Mengubah semua karakter dalam string menjadi huruf besar.
- Lowercase: Mengubah semua karakter dalam string menjadi huruf kecil.
- Capitalization: Mengubah karakter pertama setiap kata menjadi huruf besar.
Pencarian dan Penggantian
- Find: Menemukan kemunculan pertama dari pola tertentu dalam string.
- Findall: Menemukan semua kemunculan dari pola tertentu dalam string.
- Replace: Mengganti kemunculan tertentu dari pola dalam string dengan string lain.
Contoh Aplikasi
Operasi pada data sederet karakter memiliki banyak aplikasi praktis, seperti:
- Pemrosesan teks: Memisahkan teks menjadi kata atau frasa.
- Penguraian data: Mengekstrak informasi dari string kompleks.
- Validasi data: Memeriksa apakah string memenuhi kriteria tertentu.
- Pengkodean dan dekode: Mengonversi string ke dan dari format yang berbeda.
- Kriptografi: Mengenkripsi dan mendekripsi pesan menggunakan operasi string.
Contoh Penggunaan Data Sederet Karakter

Data sederet karakter adalah urutan karakter yang digunakan untuk merepresentasikan informasi. Mereka banyak digunakan dalam berbagai bidang, termasuk:
Pemrosesan Teks
- Penyimpanan dan pengambilan dokumen teks
- Pencarian dan penggantian teks
- Analisis linguistik
Penyimpanan Data
- Penyimpanan data dalam database
- Arsip dan backup data
- Transfer data antar sistem
Komunikasi
- Transmisi pesan melalui jaringan
- Penyimpanan dan pengambilan email
- Pertukaran data antar perangkat
Keunggulan dan Keterbatasan Data Sederet Karakter
| Keunggulan | Keterbatasan ||—|—|| Efisiensi penyimpanan | Rentan terhadap korupsi data || Fleksibilitas | Dapat sulit untuk diinterpretasikan || Kemudahan transmisi | Dapat membutuhkan pengkodean khusus || Dukungan luas | Mungkin tidak cocok untuk semua jenis data |
Teknik Analisis Data Sederet Karakter
Analisis data sederet karakter melibatkan proses mengekstrak informasi yang bermakna dari kumpulan data yang terdiri dari urutan karakter.
Prosedur langkah demi langkah untuk menganalisis data sederet karakter:
- Praproses data untuk membersihkan dan menyiapkan data untuk analisis.
- Terapkan algoritme segmentasi untuk membagi data menjadi unit-unit yang lebih kecil yang disebut token.
- Lakukan penandaan untuk mengidentifikasi fitur-fitur penting dari token, seperti jenis kata, tata bahasa, dan entitas yang disebutkan.
- Ekstrak informasi yang bermakna dengan menggunakan teknik pemodelan statistik, seperti pemodelan bahasa dan pembelajaran mesin.
- Evaluasi hasil analisis untuk memastikan akurasi dan keandalan.
Alat dan Teknik
- Algoritme Segmentasi: Algoritme yang membagi data menjadi token, seperti N-gram dan segmentasi berbasis aturan.
- Penandaan: Proses mengidentifikasi fitur-fitur penting dari token, seperti tagger POS dan pengidentifikasi entitas.
- Pemodelan Bahasa: Teknik statistik yang mempelajari distribusi kata-kata dalam bahasa, seperti model Markov dan model bahasa N-gram.
- Pembelajaran Mesin: Algoritme yang belajar dari data untuk mengklasifikasikan atau memprediksi hasil, seperti pohon keputusan dan jaringan saraf.
Penutupan
Memahami data sederet karakter sangat penting untuk mengelola dan memproses informasi secara efektif. Berbagai metode pengodean, operasi, dan teknik analisis telah dikembangkan untuk memanipulasi dan mengekstrak wawasan dari data jenis ini. Dengan memanfaatkan kekuatan data sederet karakter, kita dapat membuka potensi penuh informasi yang tersedia di era digital.
Pertanyaan Umum (FAQ)
Apa saja contoh data sederet karakter?
Contoh data sederet karakter meliputi teks dokumen, kode program, pesan email, dan data yang disimpan dalam file teks.
Apa saja jenis pengkodean data sederet karakter?
Jenis pengkodean data sederet karakter yang umum meliputi ASCII, Unicode, UTF-8, dan UTF-16.
Apa saja operasi yang dapat dilakukan pada data sederet karakter?
Operasi umum pada data sederet karakter meliputi penambahan, penggabungan, pemisahan, dan pencarian.